Nowadays, we often have to process large files and collect various types of data. For example, server log files from a website can be several gigabytes per day. When working with gigabyte or terabyte files, it is not always possible to have enough storage or computing capacity on a single machine. Sometimes, a machine does not have enough storage space, and sometimes, even if there is enough storage space, there is not enough RAM to load the entire file for processing. One solution is to use distributed computing, where a task is divided into smaller sub tasks and distributed among multiple machines to process in parallel. This allows for more efficient use of resources and the ability to handle larger data sets. (Original article in Bengali)
File System
If you ever set up Linux/Windows on your own computer or format a hard disk partition, you may be familiar with terms like FAT32, NTFS, EXT, etc. These are different types of file systems. The file system’s job is to manage how files are stored on your computer’s hard disk, which memory block holds which data, and how to access old data, among other things.
You can compare this to organizing your own files and documents at home. For example, you may have different folders for different types of papers, making it easy to find them later. This can also be compared to a file system.
When you format a hard drive and erase all the data, the file system is also deleted. That’s why when formatting, the system gives the option to select a file system. After formatting, a new file system is then installed on the hard drive so you can save new data.
FAT32 and NTFS are examples of disk file systems that control how data is stored on a hard drive. Your computer can have multiple hard drives, each of which can be controlled by a different file system. However, one person does not control all file systems, one file system controls one hard drive. If you want to share a file across multiple computers, you will need a distributed file system.
Distributed File System
We will now learn about architecture of an distributed file system. If you are an experienced engineer, I suggest you to take a pause and think for a while how you can design a distributed file system. Some key considerations include: how to divide a file into smaller chunks, which machine(s) will store which chunks of data, how to handle situations where a machine goes down, and how to ensure data consistency and availability in case of machine failure.
In a distributed file system, the machines are all connected within the same local network and can communicate with each other. However, typically in this type of file system, files cannot be edited after they are uploaded, and it is not intended for storing everyday word/excel files. The purpose is to store large files for offline analysis in the future.
First, we will need some machines to store the data, which we will call data nodes.

In the picture, every data node is an independent machine. Each machine has an operating system (usually Linux) installed, a hard disk, and RAM. If you have access permissions and know the IP address, you can access the machines using the ssh tool.
We will store our large files by dividing them into smaller chunks and storing them on different data nodes. However, there may be problems if a machine is running out of space or if the data is located on a specific machine, who will tell that? For this purpose, we will have a leader node. The leader node will be the manager of the entire file system and will provide information about which data is stored on which machine.
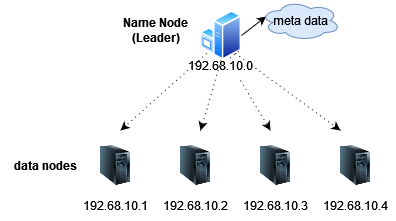
Leader node has another name called the Name Node. The reason for calling it the Name Node probably is that it keeps the name-address information of all data nodes, but I prefer the term Leader Node. Leader node also contains all the meta data. Meta data is defined as “data that provides information about other data”, in this case, file names, locations, replica numbers are examples of meta data. The Leader Node usually keeps the meta data into its memory.
Now we have got a fully functional file system, but how do we upload or read files? For this kind of operation, we need a library that the clients can use to authenticate themselves and upload or download the files.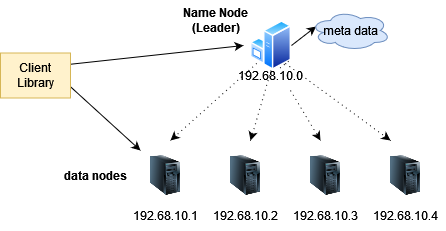 The client library has interfaces for uploading files, reading files, and browsing folders. When reading, the client library uses the name node to find out which data node the file is on, and then reads the data from that node. The client will think it is reading from a single machine, and the client library and name node handle the distribution. Because files can be very large, there is usually option for reading data in chunks.
The client library has interfaces for uploading files, reading files, and browsing folders. When reading, the client library uses the name node to find out which data node the file is on, and then reads the data from that node. The client will think it is reading from a single machine, and the client library and name node handle the distribution. Because files can be very large, there is usually option for reading data in chunks.
The process is the same for writing data. The user uses the client library’s file upload interface. The upload function connects with the name node to find out which data nodes have empty space, then the file is divided into multiple blocks and each block is sent to a different data node. The data is written in chunks.
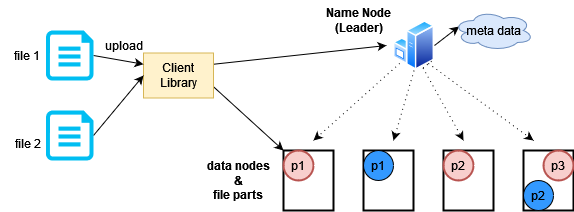
In the image above, it shows how the two files have been divided and stored on multiple data nodes.
A new problem has arisen before us now. What will happen if a data node is down for some time? Software updates, power outages, and various other reasons can cause this to happen. The solution is to keep multiple copies of each data part on different data nodes. This is called replication. This way, storage space will be used more but High Availability will be ensured. Currently, storage space is a cheap thing, so that is not a problem.
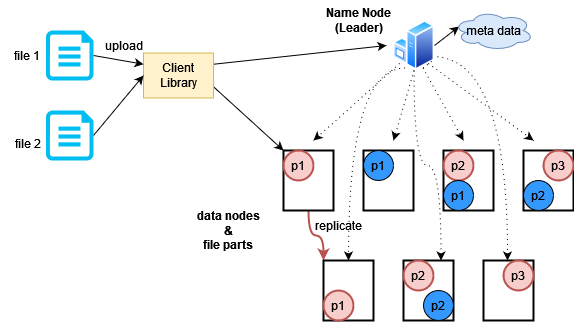
In the image, each part of the file is stored as an additional copy. If the client wants, it can update the replication number in the configuration file, but typically, at least three copies are stored. The responsibility of creating replicas lies with the data node, but the leader or name node tells which data should be copied to which node.
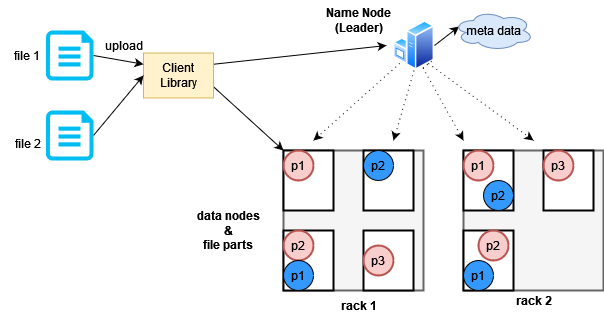
Another interesting optimization here is called Rack Awareness. Machines are kept in different racks in the data center, as shown in the image below.

Machines in the same rack generally share the same types of connections for various purposes. In case of power outages, all machines in the same rack may go down together. If the leader node knows which machine is in which rack, it can make decisions on where to place replicas during replication. It would make sense to distribute replicas across different racks.
How will the leader node know which data node is down? The leader node pings the data nodes every few seconds, and the data nodes respond, indicating that they are still alive. This is often referred to as a heartbeat check.
Another single point is still there in our design, it is the leader node. What happens when the leader node goes down? One solution is to use a secondary leader node. The secondary leader node will take over the responsibility of the leader node if it sees that the leader node has gone down. If the leader node recovers, it will take back the responsibility from the secondary leader node and the primary leader node will now be in the secondary position. However, both primary and secondary leader nodes will need to maintain a copy of the metadata.
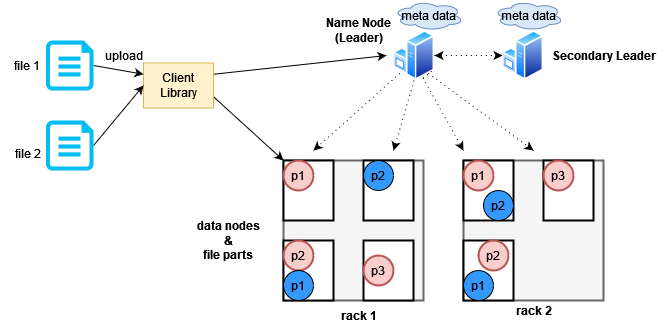 Now you may be wondering, what happens if both leader nodes go down? In reality, there is no such thing as 100% file safety in a distributed system. You can add a third leader node to increase reliability, but even that will not eliminate the possibility of system downtime. And the more nodes you add, the more expensive and complex your server bill and maintenance will become. Keeping costs low and making the site reliable is a big challenge for developers.
Now you may be wondering, what happens if both leader nodes go down? In reality, there is no such thing as 100% file safety in a distributed system. You can add a third leader node to increase reliability, but even that will not eliminate the possibility of system downtime. And the more nodes you add, the more expensive and complex your server bill and maintenance will become. Keeping costs low and making the site reliable is a big challenge for developers.
This architecture is not my imaginary design, it is the high-level architecture of Apache’s HADOOP Distributed File System (HDFS). There is also a technique for data processing in a distributed file system, which is called map-reduce. Map-reduce forms the foundation of big data processing. Google’s researchers first discovered this technique, it has a famous research paper, you can search for the map-reduce paper by name. Apache company has also created a eco-system for using map-reduce on top of HDFS, which is one of main reason why HDFS is so popular.
I used to work in the recommendation team of a big e-commerce company in Singapore. There we used to store various user data and server logs in HDFS and then use map-reduce along with other big data processing techniques to deliver product suggestions to the users. Because of splitting and storing the data in this way, were are able to easily run machine learning algorithms on large data sets. Each data node had the capability to apply the algorithm on that node, so data does not need to be transferred elsewhere.
The architecture I explained so not the end of the story, there are much more complexity related to HDFS. For example, how can we can ensure the consistency of the replicas stored in different data node? For that, there is a very complex algorithm called Paxos. HDFS implements it using a service discovery tool called Zoo Keeper. I won’t go into those details but you can research about it if you are interested.
That’s all for today, happy coding!
রেফারেন্স:
Official Documentation
Design Data Intensive Application book