Finally, the contest is over. And it’s time for the editorial of my problem. This year, I have submitted two questions for the regionals. Between these two problems, one got selected for the Dhaka regional. And that problem appeared as number H (Droplets) in the contest. Hence this problem itself was quite simple, it was supposed to be the 3rd most manageable problem of the contest. But, somehow, it turned out to be the 2nd easiest one.
[Few days before the contest, we realized that a similar problem appeared in a national-level contest in RUET. But ICPC committee decided to keep the problem because this is a much much easier version, the RUET version was one of the hardest problem in that contest.]
The Problem
The problem is about filling up a matrix with water. There is a matrix given and you have to imagine it as a 2-d box. Some parts of the matrix are enclosed. Now, you need to find out the amount of water the matrix can hold. Please read the full statement here carefully before proceeding.
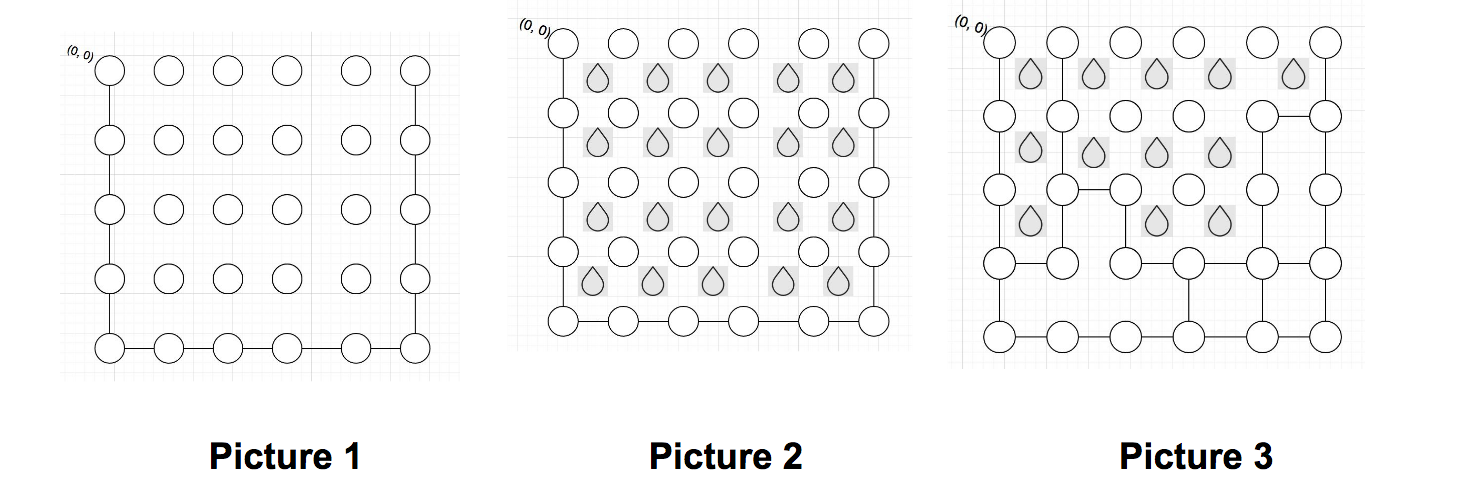
These are the pictures I used in the statement to describe the problem. What the problem asked you to do is quite clear from these pictures.
The Solution
Let’s consider the smallest unit of the matrix first to solve this problem. Here, the smallest unit is the little squares. Now, for each square in the matrix, how to identify whether there is water in the square or not?
For that to happen, the water must have a way to reach the square from the top. If you understand this part, you already know this is a graph problem. Therefore, treat every square as a node of the graph. And, a node is connected to its neighbor if no lines are blocking them.
As you have the graph now, scan the top squares from left to right. Every time you encounter a square on the first row whose top is not blocked, you found a way for the water to enter into the matrix. Afterward, run a depth-first-search from that node and mark all the nodes you can reach. Keep continuing this process, and in the end, the number of nodes you reached is the answer.
The time complexity of this solution is O(n * m) for each test case.
Here is the judge solution:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
#include <iostream> #include <cstdio> #include <cstdlib> #include <cstring> #include <cassert> using namespace std; char mat[102][102]; bool vis[102][102]; bool G[102][102][5]; //direction - top, left, bottom, right int dirx[] = {-1, +0, +1, +0}; int diry[] = {+0, -1, +0, +1}; void dfs(int i, int j, int n, int m, int &ans) { if(vis[i][j]) return; vis[i][j] = 1; ans++; for(int k = 0;k < 4;k++) { if (G[i][j][k] == 0) { int ni = i + dirx[k]; int nj = j + diry[k]; if(ni>=0 and ni < n - 1 && nj >= 0 and nj < m - 1) { dfs(ni, nj, n, m, ans); } } } } int main() { int ks = 0; int t; cin>>t; double st = clock(); while(t--) { memset(vis, 0, sizeof vis); int n, m; cin>>n>>m; for(int i = 0; i < n; i++) { cin>>mat[i]; } for(int i = 0;i < n - 1;i++) { for(int j = 0;j < m - 1;j++) { int dx = i + 1; int dy = j; int rx = i; int ry = j + 1; bool lineTop = (mat[i][j] == 'R' || mat[i][j] == 'B'); bool lineLeft = (mat[i][j] == 'D' || mat[i][j] == 'B'); bool lineBottom = (mat[dx][dy] == 'R' || mat[dx][dy] == 'B'); bool lineRight = (mat[rx][ry] == 'D' || mat[rx][ry] == 'B'); G[i][j][0] = lineTop; G[i][j][1] = lineLeft; G[i][j][2] = lineBottom; G[i][j][3] = lineRight; } } int ans = 0; for(int j = 0;j < m - 1;j++) { int i = 0; if(G[i][j][0] == 0) { dfs(i, j, n, m, ans); } } printf("Case %d: %d",++ks, ans); } double en = clock(); cerr<<(en-st)/CLOCKS_PER_SEC<<endl; return 0; } |
That’s it, I hope you enjoyed the problem!
Last but not least
Not sure whether you have noticed it or not, I have used climate-change as the theme of this problem. Recently 11000 scientists from all over the world declared a climate change emergency, which is quite alarming for all of us. Certainly, it is high time we need to be conscious about the rapidly changing climate. I am personally anxious about it, and you should be too. Let’s do whatever we can to reduce resource wastage, plastic usage, and whatever we need to save our mother planet.
Thank you.