I recently received United Kingdom Tier-1 Global Talent Visa. I have received lots of messages asking about the visa process and I couldn’t reply to everyone individually. That’s why I am writing here to share my experience.
What is UK Global Talent Visa?
The Global Talent visa is a type of UK visa offered to leaders or potential leaders in one of three fields: Academia, Arts/Culture, and Digital Technology. It allows the visa holder to live, work, or study in the UK without needing any sponsorship. There are two variations of this visa: the Exceptional Promise Route for potential leaders, and the Exceptional Talent Route for more experienced individuals.
I am a software engineer working in Meta and my expertise falls under Digital Technology. I have been working in this field since 2014, which qualified me for the Exceptional Talent Route of the Global Talent visa.
How did I get the visa?
The application process for this visa is kind of similar to typical university application in US/UK. The initial step involves obtaining an endorsement from Tech Nation, which is the only UK government-approved endorser for this field.
To get the endorsement, you need to meet one mandatory criteria and two of the four optional criteria. The mandatory criteria is the applicant must be “show that they have been recognized as a leading talent in the digital technology sector in the last 5 years.”.
Also there is a list of 4 optional criteria and I had to select two from them. I chose the first (OC1) and the second (OC2) one. For the first one, I need to prove “track record for innovation as a founder or senior executive of a product-led digital technology company or as an employee working on a new digital field or concept”. For the second one, I need to prove I have “proof of recognition for work beyond the applicant’s occupation that contributes to the advancement of the field”.
You need to submit 3 recommendation letters from experts in your field and submit up to 10 pieces of evidence to show how you meet the criteria. Also you need to submit a statement of purpose as well. The amount of paperwork needed can be a bit overwhelming at the beginning.
Now I will first tell you how did I meet each criteria. After that I will give you some tips to avoid some mistakes I made in my first application.
Meeting Optional Criteria 1 (OC1)
I am not a founder or a senior executive but the criteria also says I can show innovation “as an employee working on a new digital field or concept”. From 2017-2020 I have worked for a Indonesian startup called Traveloka in Singapore. I was one of the founding engineer of their fintech team and built couple of major products. So I requested one of the senior executive from the company to write a recommendation letter for me.
To support the recommendation letter, I have also submitted a letter from the HR of the company stating my employment period and role in the company. I also included a screenshot from my Github profile showing heat map of the code contribution for Traveloka but I am not sure if that played a significant role.
Meeting Optional Criteria 2 (OC2)
To fulfill OC2, I mainly leveraged my experience as a judge for the ACM International Collegiate Programming Contest (in the Dhaka, India, and Singapore Regionals), known as the the Olympics of programming competitions, and my published book. Shahriar Manzoor, the Dhaka Regional Director and world finals judge, provided me with a recommendation letter, emphasizing my contributions to the programming community, my tech blog, and my book.
As supporting evidence, I have attached a picture of myself awarding a prize at the final ceremony in the Singapore regional event. Also I attached screenshot of the Goodreads and Rokomari page of my book. My book was given as prize in one of the programming contest in my university, I have also used that as evidence.
Meeting Mandatory Criteria (MC)
For this, I have submitted a recommendation letter from my manager in my current job in Meta. He wrote some overview of my contributions and what sets me apart from other engineers. Also I have submitted a salary comparison for all my jobs. I have shown that I was consistently able to draw salary than average software engineer salary of the country I worked in. Of course I had to submit payslips from my jobs to support this. For this criteria, the evidences can’t be more than 5 years old.
Statement of Purpose
I had to write a SOP to make them understand how I will be beneficial for UK economy. I wrote a standard SOP talking about my startup experience and community contributions and expressed my desire to become a tech lead in a startup. Most of the startups in UK can’t sponsor visa, and a tier-1 visa can allow me to work for those companies. Looks like the reasoning was good enough.
After Getting The Endorsement
After I got the endorsement, I had to apply for the visa to UK government. They rarely reject applications if you have the endorsement unless you fail their background check. It takes 2-4 weeks on average to get the endorsement and about a month after that to get the actual visa.
The application process is not cheap, specially the health surcharge after getting the endorsement. Luckily Meta sponsored it for me but if you don’t have a sponsor, this is something to keep in mind.
Tips and Tricks
My first application was rejected (for MC and OC1) as my evidences wasn’t well organized and they mentioned some of my contributions are standard contribution for a senior software engineer. In the rejection letter they don’t give much detailed reasoning but if you appeal, they might give more details. In the next attempt, I requested the recommenders to explicitly mention why I was hired and what makes me exceptional and that time I had no issues.
If you select OC2 as optional criteria, your community contribution shouldn’t be a one time event, you need to show sustained effort over a period of time. You can start building profile by writing tech blogs, doing open source work etc. Don’t do anything just for the sake of the visa, Tech Nation don’t like that. For the recommendation letters, try to get from the senior most person possible. You also need to attach their CV or Linkedin profile to show their credentials.
The documents you submit might be slightly different if you apply for Exceptional Promise instead of Exceptional Talent. You can apply for promise if you are early in your career. The only difference between promise and talent is the time it will take to get a ILR in UK (5 years vs 3 years). One of my friend got the exceptional promise few years back, you can read his experience here.
That’s it, thank you for reading. If you have further questions, you can contact me in linkedin but do check the official website first. (Please don’t request for the copy of the letters unless you know me personally.)
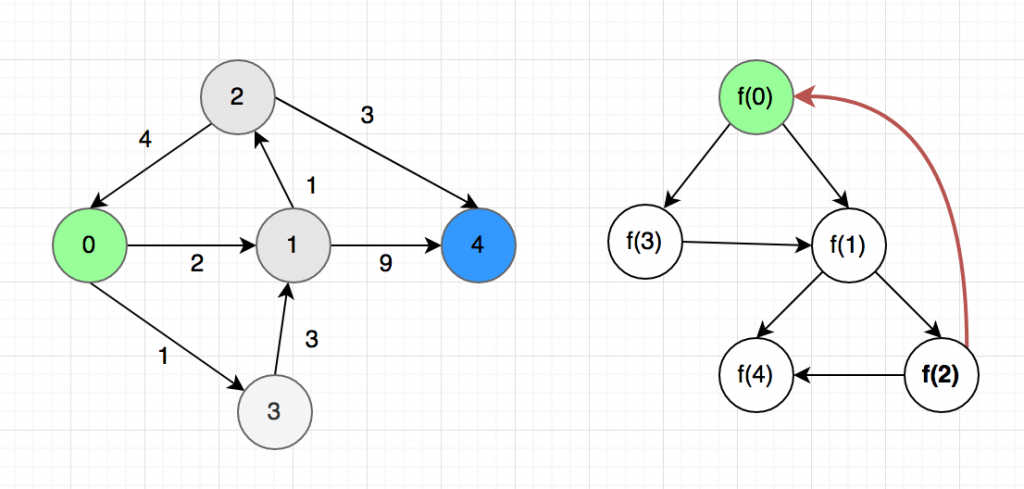
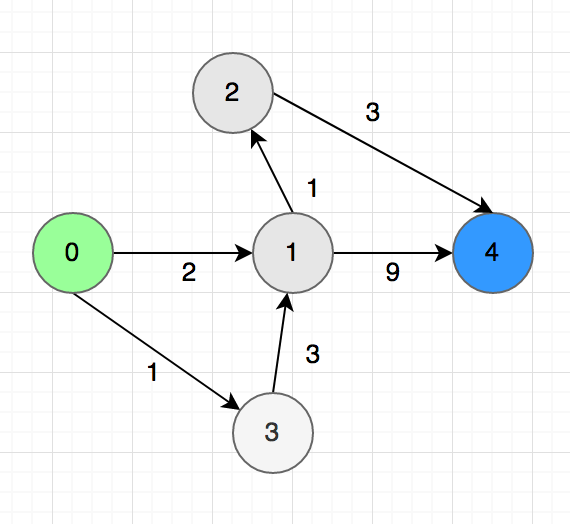
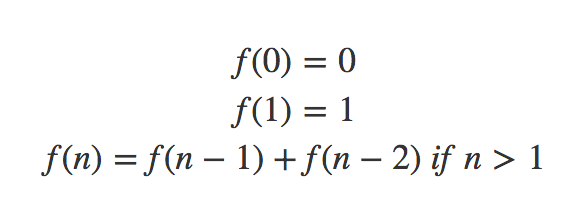
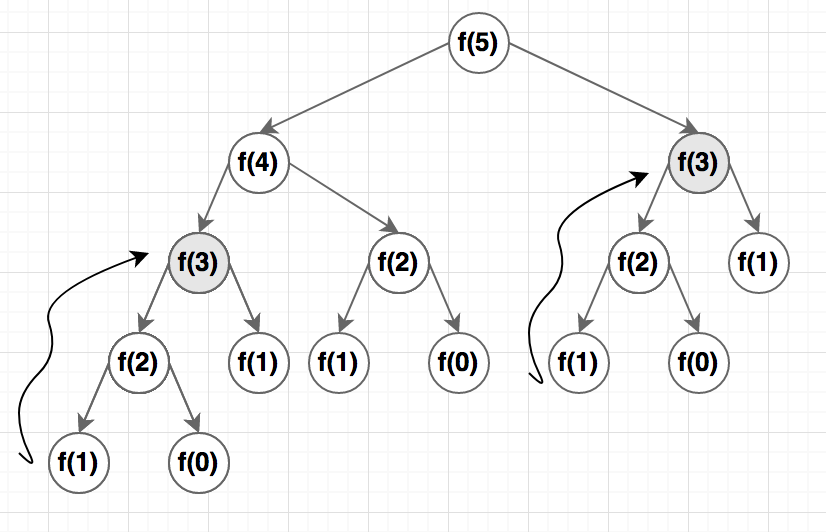


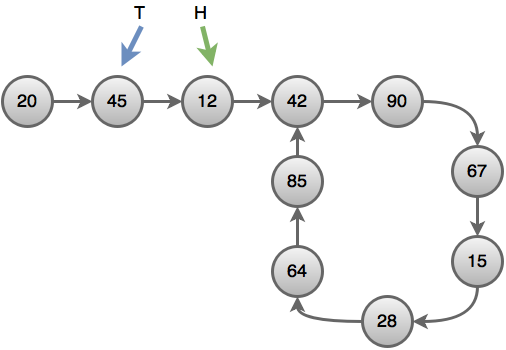





 Now you need to find a correct order to complete the tasks. There can be more than one possible solutions. Topological sort or topsort can help you to do that.
Now you need to find a correct order to complete the tasks. There can be more than one possible solutions. Topological sort or topsort can help you to do that.